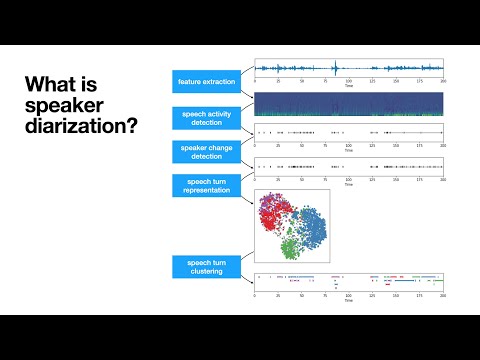
项目地址:https://github.com/pyannote/pyannote-audio
实测效果非常好,比FastWhisperGUI用的speechbrain好很多
成功实现离线部署:
下载:https://huggingface.co/pyannote/wespeaker-voxceleb-resnet34-LM/resolve/main/pytorch_model.bin 改名为models/pyannote_model_wespeaker-voxceleb-resnet34-LM.bin
下载https://huggingface.co/pyannote/segmentation-3.0/resolve/main/pytorch_model.bin改名为models/pyannote_model_segmentation-3.0.bin
创建pyannote_diarization_config.yaml文件,内容为
version: 3.1.0
pipeline:
name: pyannote.audio.pipelines.SpeakerDiarization
params:
clustering: AgglomerativeClustering
# embedding: pyannote/wespeaker-voxceleb-resnet34-LM # if you want to use the HF model
embedding: models/pyannote_model_wespeaker-voxceleb-resnet34-LM.bin # if you want to use the local model
embedding_batch_size: 32
embedding_exclude_overlap: true
# segmentation: pyannote/segmentation-3.0 # if you want to use the HF model
segmentation: models/pyannote_model_segmentation-3.0.bin # if you want to use the local model
segmentation_batch_size: 32
params:
clustering:
method: centroid
min_cluster_size: 12
threshold: 0.7045654963945799
segmentation:
min_duration_off: 0.0将三个文件放入models文件夹
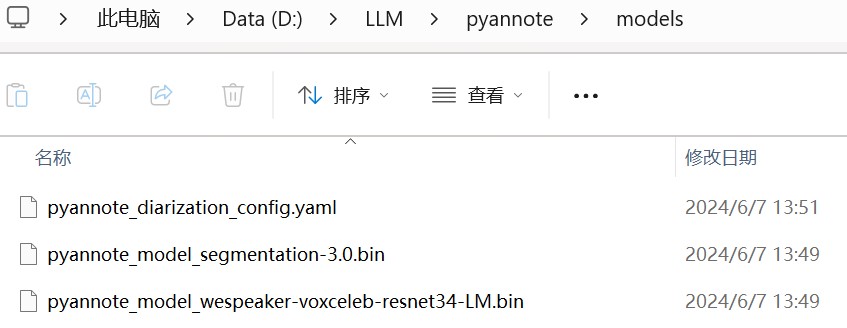
测试代码验证通过
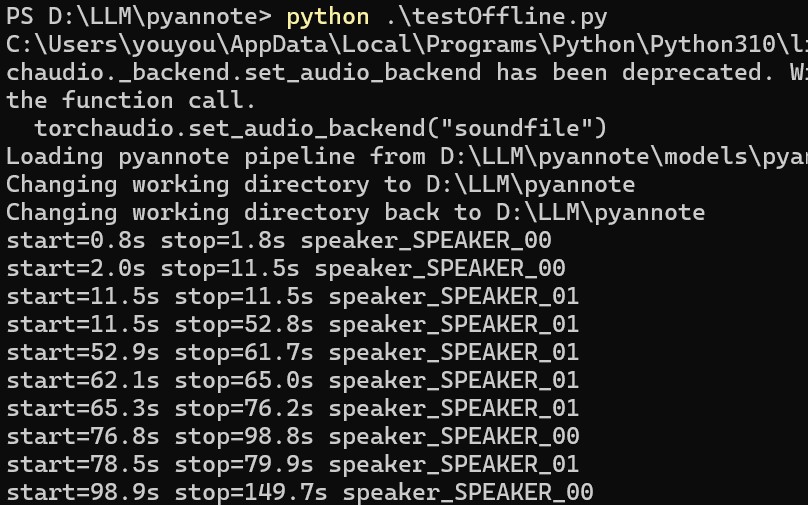
不存在https://blog.csdn.net/qq_44193969/article/details/136434417这里的问题
发表评论